Certification Matrix points to the tested & recommended configurations for Oracle software - here eg: Fusion Middleware Suite; this might not just mean supported environment though.
Notes:
* For information on Java SE (J2SE) End of Life, refer to My Oracle Support Doc ID 952075.1 on https://support.oracle.com/.
* If an Oracle product has been certified against and is supported on a version of RedHat Enterprise Linux (RHEL), it is automatically certified and supported on the corresponding version of Oracle Enterprise Linux (OEL). (e.g., RHEL4->OEL4, RHEL5->OEL5).
* If a product is supported and certified on OEL or RHEL, it is also certified and supported in the virtualized installation of the same version of OEL or RHEL running on Oracle VM. (e.g. OEL4 -> OEL4 on Oracle VM, OEL5 -> OEL5 on Oracle VM, RHEL4 -> RHEL4 on Oracle VM, RHEL 5 -> RHEL5 on Oracle VM). Oracle recommends using latest updates levels and OVM versions available.
* Every Oracle product that is certified on Windows or Solaris means it is also certified and supported when running on Windows or Solaris in a virtualized environment with Oracle VM as long as the Windows or Solaris OS is supported with Oracle VM.
Certification matrix for Oracle Fusion Middleware 11g
Certification matrix for Oracle Fusion Middleware 10g
Wednesday, October 20, 2010
Monday, October 11, 2010
XQJ - Java API for XQuery
The XQuery language allows queries to be executed against individual XML documents or collections of XML documents. The results of queries are instances of the XML Query Data Model. These instances include simple values (e.g. numbers, strings), XML nodes, and sequences of both values and XML nodes. XQuery can operate on physical XML documents or virtual XML documents that have been derived from sources of data such as relational or object databases.
XQJ (JSR 225) is a standard Java API for interacting with a variety of XQuery engines operating on XML data sources. JSR 225 specification defines a set of interfaces and classes that enable Java applications to submit XQuery queries against one or more XML data sources to an XQuery engine and consume the results.
Eg:
// obtain an XQDataSource instance
XQDataSource xqds = (XQDataSource)
Class.forName("com.jsr225.xqj").newInstance();
// obtain a connection
XQConnection con = xqds.getConnection("usr", "passwd");
// prepare an XQuery Expression
String xqry = "for $i in fn:collection('dept') " +
"where $i/deptname = %dname return count($i/employees)";
XQPreparedExpression expr = con,preparedExpression(xqry);
// bind variable with value
expr.bindString(new Qname("dname"), "engineering");
// execute the XQuery Expression
XQResultSequence rs = expr.executeQuery();
// Consume results
while (rs.next())
{
System.out.printLn(rs.getInt());
}
// clean up resources
rs.close();
con.close();
The package structure of the API would be:
javax.xml.xquery
Misc:
JSR 225
XQJ (JSR 225) is a standard Java API for interacting with a variety of XQuery engines operating on XML data sources. JSR 225 specification defines a set of interfaces and classes that enable Java applications to submit XQuery queries against one or more XML data sources to an XQuery engine and consume the results.
Eg:
// obtain an XQDataSource instance
XQDataSource xqds = (XQDataSource)
Class.forName("com.jsr225.xqj").newInstance();
// obtain a connection
XQConnection con = xqds.getConnection("usr", "passwd");
// prepare an XQuery Expression
String xqry = "for $i in fn:collection('dept') " +
"where $i/deptname = %dname return count($i/employees)";
XQPreparedExpression expr = con,preparedExpression(xqry);
// bind variable with value
expr.bindString(new Qname("dname"), "engineering");
// execute the XQuery Expression
XQResultSequence rs = expr.executeQuery();
// Consume results
while (rs.next())
{
System.out.printLn(rs.getInt());
}
// clean up resources
rs.close();
con.close();
The package structure of the API would be:
javax.xml.xquery
Misc:
JSR 225
XQuery - Querying XML 'datastore'
XQuery is a query and functional programming language that is designed to query collections of XML data. It provides the means to extract and manipulate data from XML documents or any data source that can be viewed as XML, such as relational databases or office documents.
XQuery uses XPath expression syntax to address specific parts of an XML document. It supplements this with a SQL-like "FLWOR expression" for performing joins. A FLWOR expression is constructed from the five clauses after which it is named: FOR, LET, WHERE, ORDER BY, RETURN.
XPath is query language for selecting nodes from an XML document. It has ability to navigate around the XML tree structure, selecting nodes by a variety of criteria.
Usages:
1. Extracting information from a database for a use in web service.Eg: in ESB
2. Generating summary reports on data stored in an XML database.Eg: markmail.org
3. Searching textual documents on the Web for relevant information and compiling the results.Eg: markmail.org
4. Selecting and transforming XML data to XHTML to be published on the Web.
5. Pulling data from databases to be used for the application integration.
6. Splitting up an XML document that represents multiple transactions into multiple XML documents.
Eg: http://markmail.org/ - free service for searching mailing list archives. Here, Each email is stored internally as an XML document, and accessed using XQuery. All searches, faceted navigation, analytic calculations, and HTML page renderings are performed by a small MarkLogic Server cluster running against millions of messages.
[eg: of a url on xquery ->
1. http://markmail.org/search/?q=xquery
2. http://markmail.org/search/?q=xquery#query:xquery+page:1+mid:gt5gf3btmcdwyuks+state:results]
FLWOR detailed
for $d in document("depts.xml")//deptno
let $e := document("emps.xml")//employee[deptno = $d]
where count($e) >= 10
order by avg($e/salary) descending
return
<big-dept>
for $d in document("depts.xml")//deptno
let $e := document("emps.xml")//employee[deptno = $d]
where count($e) >= 10
order by avg($e/salary) descending
return
<big-dept>
{ $d,
<headcount>{count($e)}</headcount>,
<avgsal>{avg($e/salary)}</avgsal>
}
</big-dept>
{ $d,
<headcount>{count($e)}</headcount>,
<avgsal>{avg($e/salary)}</avgsal>
}
</big-dept>
for generates an ordered list of bindings of deptno values to $d
let associates to each binding a further binding of the list of emp elements with that department number to $e
at this stage, we have an ordered list of tuples of bindings: ($d,$e)
where filters that list to retain only the desired tuples
order sorts that list by the given criteria
return constructs for each tuple a resulting value
General rules:
for and let may be used many times in any order
only one where is allowed
many different sorting criteria can be specified
for $x in /company/employee
generates a list of bindings of $x to each employee element in the company, but:
let $x := /company/employee
generates a single binding of $x to the list of employee elements in the company.
Another FLWOR eg:
Sample xml doc:
<bib>
<book>
<title>TCP/IP Illustrated</title>
<author>Stevens</author>
<publisher>Addison-Wesley</publisher>
</book>
<book>
<title>Advanced Programming
in the Unix Environment</title>
<author>Stevens</author>
<publisher>Addison-Wesley</publisher>
</book>
<book>
<title>Data on the Web</title>
<author>Abiteboul</author>
<author>Buneman</author>
<author>Suciu</author>
</book>
</bib>
Query eg: to author list and the lists of books published by each author
<authlist>
{
for $a in fn:distinct-values($bib/book/author)
order by $a
return
<author>
<name> {$a} </name>
<books>
{
for $b in $bib/book[author = $a]
order by $b/title
return $b/title
}
</books>
</author>
}
</authlist>
Result of above expression:
<authlist>
<author>
<name>Abiteboul</name>
<books>
<title>Data on the Web</title>
</books>
</author>
<author>
<name>Buneman</name>
<books>
<title>Data on the Web</title>
</books>
</author>
<author>
<name>Stevens</name>
<books>
<title>Advanced Programming
in the Unix Environment</title>
<title>TCP/IP Illustrated</title>
</books>
</author>
<author>
<name>Suciu</name>
<books>
<title>Data on the Web</title>
</books>
</author>
</authlist>
How FLWOR works:
Query to list each publisher and the average price of their books:
for $p in distinct-values(document("bib.xml")//publisher)
let $a := avg(document("bib.xml")//book[publisher = $p]/price)
return
<publisher>
<name>{ $p/text() }</name>
<avgprice>{ $a }</avgprice>
</publisher>
Operators available:
The syntax of the universal quantification expression is:
every $v in seq-expression satisfies test-expression
Eg: The following query checks if the price of every item customer 1001 orders is over 200.
# Query listing
let $price := document("data/PO.xml")
//po[customer/custno='1001']
/lineitems/lineitem/item/price
return
if (every $v in $price satisfies ( $v > 200 ) ) then
<result>
customer always orders expensive items!
</result>
else
<result>
Customer does not always order expensive items
</result>
Unless customer 1001 always orders items priced over 200, the result is
<result>
Customer does not always order expensive items
</result>
Example Implementation
Zorba - XQuery Processor
XQuery Processor embeddable in a variety of environments such as other programming languages extended with XML processing capabilities, browsers, database servers, XML message dispatchers, or smartphones. Available as API for Java.
W3C XQuery
XQJ - JSR 225
XML Querying
Zorba XQuery Processor
Excellent quick book
XQuery uses XPath expression syntax to address specific parts of an XML document. It supplements this with a SQL-like "FLWOR expression" for performing joins. A FLWOR expression is constructed from the five clauses after which it is named: FOR, LET, WHERE, ORDER BY, RETURN.
XPath is query language for selecting nodes from an XML document. It has ability to navigate around the XML tree structure, selecting nodes by a variety of criteria.
Usages:
1. Extracting information from a database for a use in web service.Eg: in ESB
2. Generating summary reports on data stored in an XML database.Eg: markmail.org
3. Searching textual documents on the Web for relevant information and compiling the results.Eg: markmail.org
4. Selecting and transforming XML data to XHTML to be published on the Web.
5. Pulling data from databases to be used for the application integration.
6. Splitting up an XML document that represents multiple transactions into multiple XML documents.
Eg: http://markmail.org/ - free service for searching mailing list archives. Here, Each email is stored internally as an XML document, and accessed using XQuery. All searches, faceted navigation, analytic calculations, and HTML page renderings are performed by a small MarkLogic Server cluster running against millions of messages.
[eg: of a url on xquery ->
1. http://markmail.org/search/?q=xquery
2. http://markmail.org/search/?q=xquery#query:xquery+page:1+mid:gt5gf3btmcdwyuks+state:results]
FLWOR detailed
for $d in document("depts.xml")//deptno
let $e := document("emps.xml")//employee[deptno = $d]
where count($e) >= 10
order by avg($e/salary) descending
return
<big-dept>
for $d in document("depts.xml")//deptno
let $e := document("emps.xml")//employee[deptno = $d]
where count($e) >= 10
order by avg($e/salary) descending
return
<big-dept>
{ $d,
<headcount>{count($e)}</headcount>,
<avgsal>{avg($e/salary)}</avgsal>
}
</big-dept>
{ $d,
<headcount>{count($e)}</headcount>,
<avgsal>{avg($e/salary)}</avgsal>
}
</big-dept>
for generates an ordered list of bindings of deptno values to $d
let associates to each binding a further binding of the list of emp elements with that department number to $e
at this stage, we have an ordered list of tuples of bindings: ($d,$e)
where filters that list to retain only the desired tuples
order sorts that list by the given criteria
return constructs for each tuple a resulting value
General rules:
for and let may be used many times in any order
only one where is allowed
many different sorting criteria can be specified
for $x in /company/employee
generates a list of bindings of $x to each employee element in the company, but:
let $x := /company/employee
generates a single binding of $x to the list of employee elements in the company.
Another FLWOR eg:
Sample xml doc:
<bib>
<book>
<title>TCP/IP Illustrated</title>
<author>Stevens</author>
<publisher>Addison-Wesley</publisher>
</book>
<book>
<title>Advanced Programming
in the Unix Environment</title>
<author>Stevens</author>
<publisher>Addison-Wesley</publisher>
</book>
<book>
<title>Data on the Web</title>
<author>Abiteboul</author>
<author>Buneman</author>
<author>Suciu</author>
</book>
</bib>
Query eg: to author list and the lists of books published by each author
<authlist>
{
for $a in fn:distinct-values($bib/book/author)
order by $a
return
<author>
<name> {$a} </name>
<books>
{
for $b in $bib/book[author = $a]
order by $b/title
return $b/title
}
</books>
</author>
}
</authlist>
Result of above expression:
<authlist>
<author>
<name>Abiteboul</name>
<books>
<title>Data on the Web</title>
</books>
</author>
<author>
<name>Buneman</name>
<books>
<title>Data on the Web</title>
</books>
</author>
<author>
<name>Stevens</name>
<books>
<title>Advanced Programming
in the Unix Environment</title>
<title>TCP/IP Illustrated</title>
</books>
</author>
<author>
<name>Suciu</name>
<books>
<title>Data on the Web</title>
</books>
</author>
</authlist>
How FLWOR works:
Query to list each publisher and the average price of their books:
for $p in distinct-values(document("bib.xml")//publisher)
let $a := avg(document("bib.xml")//book[publisher = $p]/price)
return
<publisher>
<name>{ $p/text() }</name>
<avgprice>{ $a }</avgprice>
</publisher>
Operators available:
- concatenation: ,
- set operators: | (or union), intersect, except
- functions: remove, index-of, count, avg, max, min, sum, distinct-values
- Universal Quantification Expressions
The syntax of the universal quantification expression is:
every $v in seq-expression satisfies test-expression
Eg: The following query checks if the price of every item customer 1001 orders is over 200.
# Query listing
let $price := document("data/PO.xml")
//po[customer/custno='1001']
/lineitems/lineitem/item/price
return
if (every $v in $price satisfies ( $v > 200 ) ) then
<result>
customer always orders expensive items!
</result>
else
<result>
Customer does not always order expensive items
</result>
Unless customer 1001 always orders items priced over 200, the result is
<result>
Customer does not always order expensive items
</result>
Example Implementation
Zorba - XQuery Processor
XQuery Processor embeddable in a variety of environments such as other programming languages extended with XML processing capabilities, browsers, database servers, XML message dispatchers, or smartphones. Available as API for Java.
XQuery API for Java (JSR 225)A common API that allows an application to submit queries conforming to the W3C XQuery 1.0 specification and to process the results of such queries.Refer: Blog on XQJ - JSR 225
Misc:W3C XQuery
XQJ - JSR 225
XML Querying
Zorba XQuery Processor
Excellent quick book
Tuesday, October 5, 2010
Clash of the Java rule Titans
Blaze Advisor vs JRules

Blaze Advisor and JRules continue to lead the BRMS pack in features suitable for enterprises, and both should be on the consideration list for most enterprise deployments. If you need great reporting templates, maximum speed, and lots and lots of factory support, Blaze Advisor 6.1 is probably the answer.
If rule building and rule management are more important than runtime performance -- if you need different views of the rules for different classes of users, or you want to customize the rule-building GUI and language for your business or industry -- then JRules may be the better choice. The pricing of the JRules starter pack, which includes unlimited use of BR Studio across the company, is also quite favorable.

Blaze Advisor and JRules continue to lead the BRMS pack in features suitable for enterprises, and both should be on the consideration list for most enterprise deployments. If you need great reporting templates, maximum speed, and lots and lots of factory support, Blaze Advisor 6.1 is probably the answer.
If rule building and rule management are more important than runtime performance -- if you need different views of the rules for different classes of users, or you want to customize the rule-building GUI and language for your business or industry -- then JRules may be the better choice. The pricing of the JRules starter pack, which includes unlimited use of BR Studio across the company, is also quite favorable.
DayLight Saving - When clock hands tick an hour ahead..
Guys, the spring is back! now time for 'time' to tick an hour ahead...
Hope you don't forget the catchup by being an hour late ;)
In NSW-Vic 2010
Daylight Saving Begins - Sunday 3 October 2010 at 2:00 am
 Daylight Saving ends - Sunday 3 April 2011 at 3:00 am
Daylight Saving ends - Sunday 3 April 2011 at 3:00 am
 What is Daylight saving ?!
What is Daylight saving ?!
A practice of temporarily advancing clocks during warmer months so that afternoons have more daylight and mornings have less. Typically clocks are adjusted forward one hour near the start of spring and are adjusted backward in autumn.
This was first suggested by a Kiwi - GV Hudson in 1895.
Effects
Adding daylight to afternoons benefits retailing, sports, and other activities that exploit sunlight after working hours, but causes problems for farming, evening entertainment and other occupations tied to the sun. Although an early goal of DST was to reduce evening usage of incandescent lighting, formerly a primary use of electricity (modern heating and cooling usage patterns differ greatly, and research about how DST currently affects energy use is limited or contradictory).
When
A one-hour shift occurs at 02:00 local time, in spring the clock jumps forward from 02:00 standard time to 03:00 DST and that day has 23 hours, whereas in autumn the clock jumps backward from 02:00 DST to 01:00 standard time, repeating that hour, and that day has 25 hours. A digital display of local time does not read 02:00 exactly at the shift, but instead jumps from 01:59:59.9 either forward to 03:00:00.0 or backward to 01:00:00.0. In this example, a location observing UTC+10 during standard time is at UTC+11 during DST; conversely, a location at UTC-10 during standard time is at UTC-9 during DST.
Oz Facts
Australia has three standard time zones from GMT:
NSW, ACT, Victoria, South Australia, and Tasmania observe daylight saving time every year. WA, Queensland and NT don't.
Linux, Java (since JRE 1.4 in 2002) and Oracle (since 9i in 2004) uses TZ (timezone) databasefor time zone processing and conversions
Eg:
Get Current Time Zone
SELECT DBTIMEZONE FROM dual;
Converts a timestamp value at a time zone to a TIMESTAMP WITH TIME ZONE value
SELECT FROM_TZ(TIMESTAMP '2007-11-20 08:00:00', '3:00') FROM dual;
Returns the Time Zone Offset
SELECT TZ_OFFSET('US/Eastern') FROM dual;
Misc:
Holidays in NSW
Oracle TZ


Hope you don't forget the catchup by being an hour late ;)
In NSW-Vic 2010
Daylight Saving Begins - Sunday 3 October 2010 at 2:00 am


A practice of temporarily advancing clocks during warmer months so that afternoons have more daylight and mornings have less. Typically clocks are adjusted forward one hour near the start of spring and are adjusted backward in autumn.
This was first suggested by a Kiwi - GV Hudson in 1895.
Effects
Adding daylight to afternoons benefits retailing, sports, and other activities that exploit sunlight after working hours, but causes problems for farming, evening entertainment and other occupations tied to the sun. Although an early goal of DST was to reduce evening usage of incandescent lighting, formerly a primary use of electricity (modern heating and cooling usage patterns differ greatly, and research about how DST currently affects energy use is limited or contradictory).
When
A one-hour shift occurs at 02:00 local time, in spring the clock jumps forward from 02:00 standard time to 03:00 DST and that day has 23 hours, whereas in autumn the clock jumps backward from 02:00 DST to 01:00 standard time, repeating that hour, and that day has 25 hours. A digital display of local time does not read 02:00 exactly at the shift, but instead jumps from 01:59:59.9 either forward to 03:00:00.0 or backward to 01:00:00.0. In this example, a location observing UTC+10 during standard time is at UTC+11 during DST; conversely, a location at UTC-10 during standard time is at UTC-9 during DST.
Oz Facts
Australia has three standard time zones from GMT:
- AWST (western UTC+08 - WA),
- ACST (central UTC+09:30 followed by SA & NT) and
- AEST (eastern, UTC+10 followed by other states)
NSW, ACT, Victoria, South Australia, and Tasmania observe daylight saving time every year. WA, Queensland and NT don't.
- NSW, ACT,Vic and Tas move from AEST to Australian Eastern Daylight Time (AEDT), and clocks are advanced to UTC +11.
- SA and the NSW town of Broken Hill move from ACST to Australian Central Daylight Time (ACDT), and clocks are advanced to UTC +10 ½.
- Broken Hill, NSW follows ACST
- Lord Howe Island follows GMT+10:30
- Residents of towns on the Eyre Highway (including Eucla, Caiguna, Madura, Mundrabilla and Border Village) in south-east corner of WA follows UTC+8:45
Linux, Java (since JRE 1.4 in 2002) and Oracle (since 9i in 2004) uses TZ (timezone) databasefor time zone processing and conversions
Eg:
Get Current Time Zone
SELECT DBTIMEZONE FROM dual;
Converts a timestamp value at a time zone to a TIMESTAMP WITH TIME ZONE value
SELECT FROM_TZ(TIMESTAMP '2007-11-20 08:00:00', '3:00') FROM dual;
Returns the Time Zone Offset
SELECT TZ_OFFSET('US/Eastern') FROM dual;
Misc:
Holidays in NSW
Oracle TZ
Oz DST calendar
Sunrise & Sunset during DST
Clock shifts affecting apparent sunrise and sunset times at Greenwich (reference centre point for Timezone region).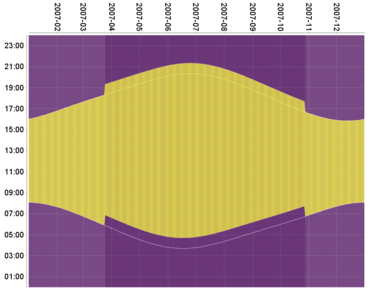
Subscribe to:
Comments (Atom)